Linux内存资源分析
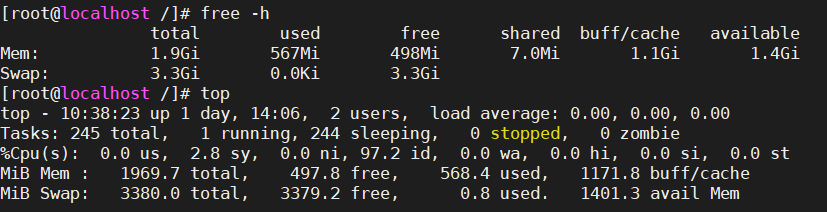
Cache与Buffer的区别
1. 物理流向:数据的搬运
- Disk → Buffer:数据从磁盘读到内存的Buffer区域。这个过程通常由DMA(直接内存访问)完成,不占用CPU。
- Buffer → Cache:数据从Buffer拷贝到Cache。这一步的“拷贝”有时是显式的(如传统I/O),有时是逻辑上的共享(如
mmap)。 - Cache → CPU:CPU直接从Cache读取数据进行计算。
2. 核心区别:Buffer vs Cache
这是理解这张图的关键,也是最容易混淆的地方:
- Buffer(缓冲区):“为了写”。
- 它的主要作用是缓解速度差异,或者攒一批数据再处理。
- 在你这张图里,Buffer紧邻Disk。它的存在是为了积攒从磁盘来的数据流,防止CPU频繁被打断去处理单个字节;或者反过来,将要写入磁盘的数据攒成一大块再一次性写入。
- 对象是磁盘(块设备)。
- Cache(缓存)):“为了读”。
- 它的主要作用是避免重复计算/读取。
- 它的存在是因为CPU下一次很可能还要用同一份数据,直接放在Cache里,下次CPU来取的时候瞬间就能拿到,不用再去底层(Buffer甚至Disk)重新搬一遍。
- 对象是数据(文件内容),服务对象是CPU/应用程序。
3. 业务流程举例
假设CPU要读取一个文件:
- 查Cache:CPU先去Cache里看,有没有我要的数据?
- Cache Miss:Cache里没有。
- 去Buffer找:Cache知道这个数据在磁盘的哪个位置,它会让Buffer去把这块数据从Disk拉进来。
- Buffer读盘:Buffer向磁盘发起I/O请求,磁盘把数据扇区读入Buffer。
- 填入Cache:Buffer把数据转交给Cache(Page Cache)。
- CPU处理:CPU从Cache中取走数据。
4. 为什么要把Buffer和Cache分开画?
在早期的操作系统(或非常底层的嵌入式系统)中,Buffer和Cache在内存里是不同的区域,职责分明。
虽然在现代Linux系统中,你通过free命令看到的buff/cache已经很难严格区分,很多场景下它们共享同一片内存池(Page Cache既充当缓存也充当缓冲区),但在概念架构分析或性能调优(如直接I/O绕过Cache、裸设备读写绕过Buffer)时,这种区分依然非常重要。
如何清除cache与buffer
1、仅清除页面缓存PageCache方法:
echo 1 > /proc/sys/vm/drop_caches
2、清除目录项和inode节点:
echo 2 > /proc/sys/vm/drop_caches
3、清除页面缓存、目录项和inode节点:
echo 3 > /proc/sys/vm/drop_caches
内存不足时,系统回收内存步骤
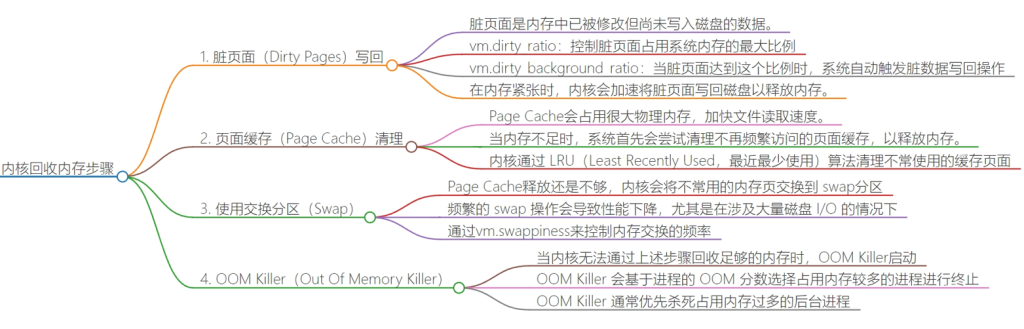
这张图完整展示了Linux内存回收机制的四个层级,从温和的异步回写,到强制的同步回收,再到极端情况下的杀进程保系统。
这是一个由轻到重、逐级递进的内存紧张处理流程。我们按顺序拆解:
第一层:脏页面写回 —— 腾出“干净”内存
背景:
应用程序修改了文件(如写入日志),数据先存在Page Cache里。此时这些页面是脏的——内存里有最新数据,磁盘里还是旧数据。
目的:
把脏页面刷到磁盘,把它们变成干净页面。干净页面可以直接回收(丢弃),或者被其他进程复用。
关键参数:
vm.dirty_ratio:脏页占系统内存的绝对上限(默认20%)。到达此值后,所有后续写入操作都会阻塞,强制刷盘。vm.dirty_background_ratio:脏页达到此比例(默认10%),内核后台异步启动回写线程,不阻塞应用程序。
在图中位置:
这是第一道防线。内存还没到极紧张状态,先加速把脏数据落盘,把“脏”变“干净”。
第二层:页面缓存清理 —— 回收“冷”数据
背景:
如果脏页面刷完了,内存还是不够,说明系统里有很多不再频繁访问的干净缓存(如刚解压完的安装包、读完没再用的配置文件)。
目的:
把这些最近最少使用的缓存页直接扔掉。
机制:
- 内核维护LRU链表。
- 内存紧张时,从链表尾部开始回收。
- 如果页面是干净的,直接回收;如果是脏的,先写回再回收(进入第一层)。
关键点:
- 这层不涉及磁盘写入(除非遇到脏页),只是丢掉缓存。
- 这是成本最低的内存回收方式。
第三层:使用交换分区 —— 内存“换出”
背景:
缓存清得差不多了,内存还是不够。但进程们确实占用了大量匿名页(如堆、栈、malloc分配的内存),这些页面没有对应的磁盘文件。
目的:
把不常用的进程内存页偷出来,暂时存到磁盘的swap分区。
代价:
- 极慢。内存纳秒级,磁盘毫秒级,差了百万倍。
- 频繁swap = 系统变卡,磁盘I/O打满。
控制参数:
vm.swappiness(0–100):- 并不是“swap开关”,而是倾向于使用swap的程度。
- 值越高,内核越愿意把匿名页换出,而不是去回收文件缓存。
- 值越低(如0),内核会尽可能先清缓存,直到万不得已才swap。
第四层:OOM Killer —— 保命机制
背景:
缓存清了,swap也用了,内存还是不够(比如某个进程疯狂malloc)。再这样下去系统会彻底卡死,连sshd都无法响应。
目的:
杀死一个进程,立刻释放它的全部内存。
机制:
- 每个进程有一个
oom_score。 - 占用内存越多,分数越高。
- 运行时间越短,分数越高。
- root权限进程、核心服务有保护。
- OOM Killer选择分数最高的进程杀掉。
- 日志会记录在
dmesg或/var/log/messages。
关键点:
- 这是最后手段。走到这一步意味着系统已经濒临崩溃。
- 如果被杀的进程是关键服务(如数据库),后果是业务中断。
整体逻辑总结
| 层级 | 动作 | 代价 | 典型场景 |
|---|---|---|---|
| 1 | 加速刷脏页 | 磁盘写入 | 脏页比例超标 |
| 2 | 丢弃缓存页 | 几乎无(下次读盘) | 文件缓存占满 |
| 3 | 换出到swap | 极高(磁盘I/O) | 物理内存不足 |
| 4 | 杀进程 | 业务中断 | 内存完全耗尽 |
一句话概括:
先刷脏、再丢缓存、再换出、最后杀人。
常见调优思路
- 如果磁盘极慢(如机械盘):
- 调低
vm.dirty_ratio(如5%),避免一次刷太多导致卡顿。 - 调低
vm.swappiness(如10),尽量不碰swap。
- 如果内存极贵(如云服务器):
- 开swap(但注意磁盘IOPS限额)。
- 适当调高
vm.vfs_cache_pressure,让内核更积极回收dentry/inode缓存。
- 如果业务要求低延迟:
- 关闭swap(
swapoff)。 - 内存预留(
vm.min_free_kbytes)。
这四层是Linux内核内存管理的标准动作,理解了它们,就能看懂free、top、vmstat里很多指标的含义。
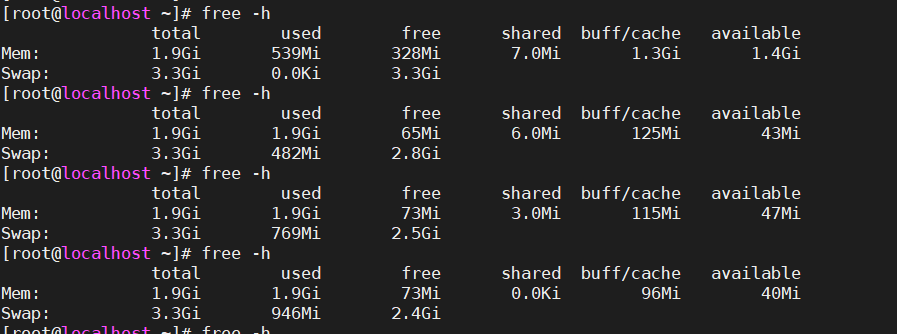
压力测试
yum install -y epel-release yum install -y stress stress-ng # 申请 2GB 内存,持续 60 秒 stress --vm 1 --vm-bytes 2G --timeout 60s

发表回复