我使用的是一台rocky9.2的服务器,登录用户为普通用户liao(有sudo权限)
sudo ls -lh /var/log/messages #查看日志大小
sudo wc -l /var/log/messages #查看日志行数

好的,图中可以看出我的日志大小为580k,日志的行为6260
# 实时监控
tail -f /var/log/messages #-f显示最后十行,也可以自行指定
比如
# 查看最后100行
tail -100 /var/log/messages
# 查看前50行
head -50 /var/log/messages
sudo tail -f /var/log/messages这个命令输入后,其输出的命令是实时更新的
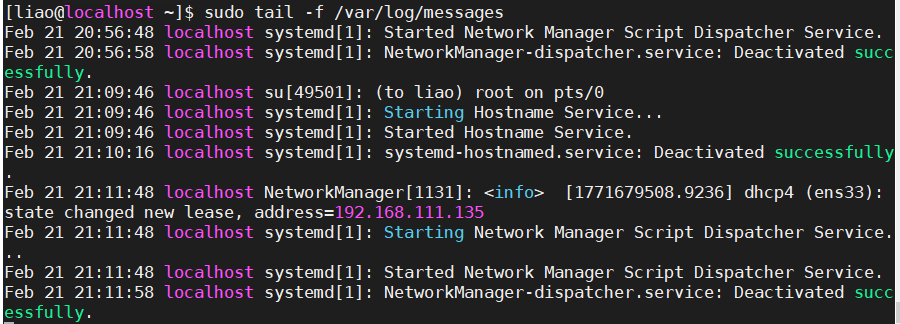
以下是重点精简的内容
20:56 – NetworkManager的脚本调度服务启动又关闭(正常任务完成)
21:09 – root用户切换到liao用户,触发了主机名服务,30秒后自动关闭
21:11 – 网卡ens33获取到新IP地址192.168.111.135(DHCP租约更新)
21:11 – IP变更触发NetworkManager脚本调度服务,处理完网络事件后10秒自动退出
按时间过滤
# 查看今天的日志 grep "$(date +%b\ %e)" /var/log/messages # 查看特定时间范围 grep "Feb 21 1[0-9]" /var/log/messages # 10-19点 grep "Feb 21 1[5-6]" /var/log/messages # 15-16点
sudo grep “Feb 21 20” /var/log/messages #查看二月21号20点这个时间段的日志
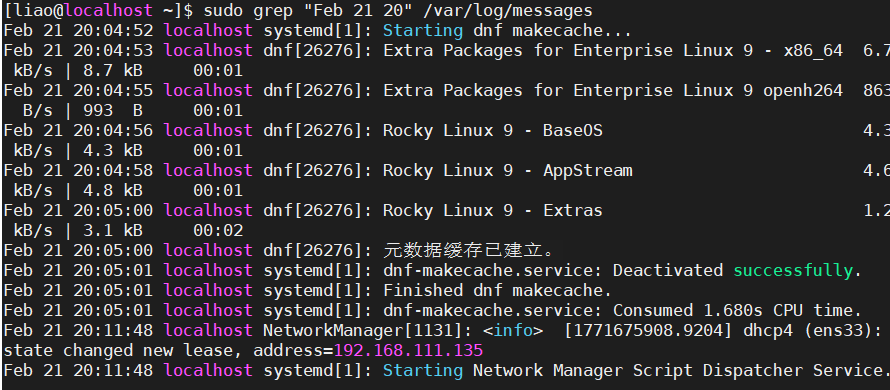
如上图就是这个时间段的日志,由于后面还有很多太长了,所有这里只截取一部分
grep -i error /var/log/messages #错误日志分析命令
sudo tail -f /var/log/messages | grep -i error #在这里我遇到一个小问题,如下图

然后我用工具搜素了一下,在第一次sudo tail -f /var/log/messages | grep -i error后,说是缓冲的问题,然后推荐我用下面的那个,然后我用了过后还是没有输出,然后我就再搜了一下,最后说是因为最近十行可能没有错误,在这里产生了一个误区,最开始我是以为所说的输出错误是最近10次的错误,最后发现其是在最后十行中grep查找error错误输出,这其实也是自身对grep掌握还不够熟练导致的。

然后我改成了查找最后的1000行,这时就有了错误输出
sudo tail -n 100 -f /var/log/messages #这个命令是先查看最后100行,然后实时监控
grep -i “fail” /var/log/messages #这个是查看fail的日志
| 命令 | 搜索内容 | 典型匹配场景 |
|---|---|---|
grep -i "fail" /var/log/messages | 包含 fail 的行 | 失败、故障(如登录失败、服务启动失败) |
grep -i error /var/log/messages | 包含 error 的行 | 错误(更严重的问题) |
简单来说:fail 偏向于”失败”(操作层面的),error 偏向于”错误”(系统层面的),两者经常一起使用来全面排查问题。
除此之外还有warn级别的,下表是三者对比
| 对比项 | error | fail | warn |
|---|---|---|---|
| 中文含义 | 错误 | 失败 | 警告 |
| 严重程度 | 高 | 高 | 中 |
| 是否影响功能 | 是 | 是 | 暂时不影响 |
| 是否需要处理 | 必须 | 必须 | 建议关注 |
| 典型场景 | 系统错误、硬件错误、程序崩溃 | 登录失败、启动失败、操作失败 | 资源不足、配置问题、潜在风险 |
| 示例 | “kernel error” “I/O error” | “login failed” “service failed to start” | “disk space low” “deprecated function” |
sudo tail -n 500 -f /var/log/messages | grep -i –line-buffered -E “error|warn|fail” #这个是同时查看近五百行三者的错误,并且实时显示
发表回复