正则表达式就是由一系列特殊字符组成的字符串,简称RE(Regular Expression)。其中每个特殊字符都被称为元字符, 这些元字符并不表示为它们字面上的含义, 而会被解释为一些特定的含义。
正则表达式是由普通字符和元字符共同组成的集合, 这个集合用来匹配(或指定)模式
正则表达式的主要功能是文本查询和字符串操作,正则表达式可以匹配文本的一个字符或字符集合。
a、b、1、2等字符属于普通字符,普通字符可以按照字面意思理解,如:a只能理解为英文的小写字母a,没有其他隐藏含义。
而*、^、[]等元字符,Shell赋予了它们超越字面意思的意义,如:*符号的字面意义只是一个符号,而实际上却表示了重复前面的字符0次或多次的隐藏含义。
一个正则表达式包含下列一项或多项: ^linux*
一个字符集. 这里所指的字符集只包含普通字符, 这些字符只表示它们的字面含义. 正则表达式的最简单形式就是只包含字符集, 而不包含元字符.
锚. 锚指定了正则表达式所要匹配的文本在文本行中所处的位置. 比如, ^, 和$就是锚.
修饰符. 它们扩大或缩小(修改)了正则表达式匹配文本的范围. 修饰符包含星号, 括号, 和反斜杠.
| 符号 | 意义 |
| * | 0个或多个在*字符之前那个普通字符 |
| . | 匹配任意Y一个字符 |
| ^ | 匹配行首,或后面字符的非 |
| $ | 匹配行尾 |
| [] | 匹配字符集合 |
| \ | 转义符,屏蔽一个元字符的特殊意义 |
| \<\> | 精确匹配符号 |
| \{n\} | 匹配前面字符出现n次 |
| \{n,\} | 匹配前面字符至少出现n次 |
| \{n,m\} | 匹配前面字符出现n次与m次之间 |
符号用于匹配前面一个普通字符的0次或多次重复 helo: 符号前面的普通字符是l,字符就表示匹配l字符0次或多次,如字符串helo、hello、hellllllo,heo都可以由hel*o来表示
.符号用于匹配任意一个字符
| 模式 | 含义 | 匹配示例 | 不匹配示例 |
|---|---|---|---|
c.t | c + 任意1字符 + t | cat, cut, c+t, c2t | ct (缺1字符),cart (多1字符) |
a..b | a + 任意2字符 + b | a12b, a+_b, a b | ab (缺字符),a123b (多字符) |
... | 任意3个字符 | abc, 123, a b | ab (只有2个) |
^...$ | 整行正好3字符 | cat, dog, 123 | cats (4字符) |
^符号用于匹配行首,表示行首的字符是^字符后面的那个字符
^cloud表示匹配以cloud开头的行
| 位置 | 含义 | 示例 | 说明 |
|---|---|---|---|
^ 在模式开头 | 行首 | ^abc | 匹配以abc开头的行 |
^ 在 [^ 里 | 排除 | [^abc] | 匹配不是a/b/c的字符 |
$符号匹配行尾,$符号放在匹配字符之后
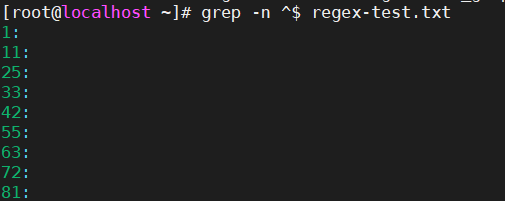
abc$ # 匹配以 “abc” 结尾的行 [0-9]$ # 匹配以数字结尾的行 ^$ # 匹配空行(行首紧接着行尾)
示例说明:
| 模式 | 含义 | 匹配的行 |
|---|---|---|
hello$ | 以hello结尾 | “say hello”, “hello” |
\.txt$ | 以.txt结尾 | “file.txt”, “data.txt” |
[0-9]$ | 以数字结尾 | “page1”, “item2” |
^$ | 空行 | 什么都没有的行 |
对比 ^ 和 $:
| 符号 | 位置 | 含义 | 示例 |
|---|---|---|---|
^ | 放在模式开头 | 匹配行首 | ^start |
$ | 放在模式结尾 | 匹配行尾 | end$ |
micky$表示匹配以micky结尾的所有行
^$ 表示空白行
[]匹配字符的一个集合,在RE中, 将匹配中括号字符集中的某一个字符
“[xyz]” 将会匹配字符x, 或y, 或z.
“[c-n]” 匹配字符c到字符n之间的任意一个字符.
“[B-Pk-y]” 匹配从B到P, 或者从k到y之间的任意一个字符.
“[a-z0-9]” 匹配任意小写字母或数字.
“[^b-d]” 将会匹配范围在b到d之外的任意一个字符. 这就是使用^对字符集取反的一个实例.
将多个中括号字符集组合使用, 能够匹配一般的单词或数字. “[Yy][Ee][Ss]”能够匹配yes, Yes, YES, yEs, 等等. “[0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9][0-9][0-9]” 可以匹配社保码
举例:grep “[^a-z]” exp2.txt
反斜杠 \ 的核心作用
反斜杠用来”脱掉”特殊字符的特殊外衣,让它们回归字面含义
1. 转义特殊字符
\$ # 匹配字符"$"(不是行尾)
\^ # 匹配字符"^"(不是行首)
\. # 匹配字符"."(不是任意字符)
\* # 匹配字符"*"(不是重复)
\\ # 匹配字符"\"(反斜杠本身)2. 给普通字符赋予特殊含义
\< # 单词开头边界
\> # 单词结尾边界
\b # 单词边界(有些版本)
\B # 非单词边界转义尖括号 \<...\> 详解
\<the\> # 精确匹配单词"the"
# 匹配:the
# 不匹配:them, there, other, theater 大括号 \{\} 重复次数
| 模式 | 含义 | 示例 | 匹配 |
|---|---|---|---|
\{n\} | 恰好n次 | JO\{3\}B | JOOOB |
\{n,\} | 至少n次 | JO\{3,\}B | JOOOB, JOOOOB, JOOOOOB |
\{n,m\} | n到m次 | JO\{3,6\}B | JOOOB(3), JOOOOB(4), JOOOOOB(5), JOOOOOOB(6) |
[a-z]\{5\} | 5个小写字母 | [a-z]\{5\} | hello, house, world |
例子解析
grep "\<iivey\>" exp1.txt这条命令的含义:
\<– 单词开头边界iivey– 要匹配的单词\>– 单词结尾边界- 整体:精确匹配单词 “iivey”
更多例子
# 匹配恰好3个数字
grep "[0-9]\{3\}" file.txt
# 匹配至少2个大写字母
grep "[A-Z]\{2,\}" file.txt
# 匹配2-4个重复的o
grep "o\{2,4\}" file.txt
# 匹配完整的单词"hello"
grep "\<hello\>" file.txt
# 匹配句号(转义)
grep "\." file.txt- 反斜杠 = 脱掉特殊外衣,回归字面
- 转义尖括号 = 赋予单词边界含义
- 大括号 = 控制重复次数
扩展正则元字符详解
| 元字符 | 名称 | 含义 | 示例 | 匹配 | 不匹配 |
|---|---|---|---|---|---|
? | 问号 | 匹配前面字符0次或1次 | colou?r | color, colour | colouur |
+ | 加号 | 匹配前面字符至少1次 | fe+el | feel, feeel | fel |
() | 圆括号 | 分组 | (ab)+ | ab, abab | a, b |
| | 竖线 | 或操作 | cat|dog | cat, dog | catdog |
POSIX字符类
为了保持不同国家的字符编码的一致性,POSIX(Portable Operating System Interface)增加了特殊的字符类,以[:classname]的格式给出,grep命令支持POSIX字符类,
| 类名 | 意义 | 等价于 | 示例 | 匹配 | 不匹配 |
|---|---|---|---|---|---|
| [:upper:] | 大写字母 | [A-Z] | [[:upper:]] | A, Z, FOO | a, z, 123 |
| [:lower:] | 小写字母 | [a-z] | [[:lower:]] | a, z, hello | A, Z, 123 |
| [:digit:] | 阿拉伯数字 | [0-9] | [[:digit:]] | 0, 5, 9 | a, Z, @ |
| [:alnum:] | 字母和数字 | [0-9a-zA-Z] | [[:alnum:]] | a, Z, 9 | @, !, 空格 |
| [:space:] | 空白字符 | 空格、Tab等 | [[:space:]] | 空格, \t | 字母, 数字 |
| [:alpha:] | 大小写字母 | [a-zA-Z] | [[:alpha:]] | a, Z, Hello | 9, @, 空格 |
| [:cntrl:] | 控制字符 | ASCII 0-31 | [[:cntrl:]] | Ctrl+A, Ctrl+B | a, 1, @ |
| [:graph:] | 可见字符 | ASCII 33-126 | [[:graph:]] | a, Z, 9, @, ! | 空格, Tab |
| [:print:] | 可打印字符 | 可见字符+空格 | [[:print:]] | a, Z, 9, 空格 | 控制字符 |
| [:xdigit:] | 十六进制数字 | [0-9A-Fa-f] | [[:xdigit:]] | 0, 5, A, F, b | G, Z, 7 (非十六进制 |
通配
通配(globbing)是把一个包含通配符的非具体文件名扩展到存储在计算机、服务器或者网络上的一批具体文件名的过程
最常用的通配符包括正则表达式元字符:?、*、[]、{}、^等,通配符与元字符意义不完全相同:
*符号不再表示其前面字符的重复,而是表示任意位的任意字符
?字符表示一位的任意字符
^符号在通配中不代表行首,而是代表取反意义
通配符 vs 正则表达式 核心区别
| 符号 | 通配符 (globbing) | 正则表达式 (regex) |
|---|---|---|
* | 任意长度的任意字符 | 前一个字符重复0次或多次 |
? | 单个任意字符 | 前一个字符重复0次或1次(ERE) |
[] | 匹配括号内任一字符 | 匹配括号内任一字符 |
{} | 匹配花括号内任一字符串 | 分组 |
^ | 在[]开头表示取反 | 行首 或 在[]内取反 |
发表回复