我们来把分布式计算集群这个概念彻底讲透,让你不仅理解文字定义,更能明白它和前面讲的高可用集群、负载均衡集群有什么本质不同。
第一讲:什么是分布式计算集群?—— 从”多人干活”到”合力解难题”
想象一下这三个场景:
- 高可用集群(HA):一个厨师炒菜,一个厨师在旁边等着接班——目的是服务不中断。
- 负载均衡集群(LB):一个调度员,多个厨师一起炒菜——目的是分摊流量。
- 分布式计算集群(Distributed Computing):现在不是炒菜了,而是要破解一个极其复杂的密码。一个厨师脑子不够用,需要把密码拆成1万段,找来1万个厨师,每人算一小段,最后把结果拼起来。
这就是分布式计算集群的核心:
把一个巨大的计算任务,拆分成无数个小任务,分给成百上千台机器同时计算,最后汇总结果。
你文档里提到的”单个计算机所不能提供的强大计算能力”,就是这个意思。
第二讲:它与前两种集群的本质区别
为了让你彻底分清这三种集群,我画个对比表:
| 维度 | 高可用集群 (HA) | 负载均衡集群 (LB) | 分布式计算集群 |
|---|---|---|---|
| 核心目标 | 保命(服务不中断) | 分忧(分摊流量) | 攻坚(解决超大计算问题) |
| 任务特点 | 同一任务,备份执行 | 同一任务,多机分担 | 一个大任务,拆碎后并行计算 |
| 数据一致性 | 数据要同步(共享存储) | 数据要一致(代码相同) | 数据要切分(每个节点拿一块) |
| 典型代表 | Heartbeat, Keepalived | LVS, Nginx, HAProxy | Hadoop, Spark, MPI |
| 比喻 | 皇帝的替身 | 餐厅的后厨团队 | 破解密码的万人团队 |
关键区别:
- HA和LB处理的是请求,分布式计算处理的是数据和计算。
- HA和LB追求的是响应速度,分布式计算追求的是吞吐量和计算能力。
第三讲:Hadoop——分布式计算的”祖师爷”
你文档里提到了Hadoop,这是目前最经典的分布式计算框架。我们来把它拆解清楚。
1. Hadoop的两大核心
Hadoop主要由两部分组成,正好对应你文档里写的内容:
| 组件 | 全称 | 作用 | 比喻 |
|---|---|---|---|
| HDFS | Hadoop Distributed File System | 分布式文件系统,把文件切块存到多台机器上 | 一个超大文件被切成拼图块,分散保存在各地 |
| MapReduce | Map + Reduce | 分布式计算框架,把计算任务拆碎(Map)再汇总(Reduce) | 先分头查资料(Map),再汇总写报告(Reduce) |
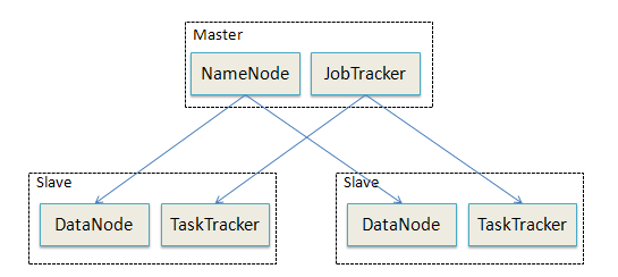
2. 集群中的角色分工(重点理解)
你文档里提到的Master和Slave,我来把它们对应清楚:
Master节点(老大)—— 负责指挥调度
| 角色 | 职责 | 比喻 |
|---|---|---|
| NameNode (HDFS的Master) | 管理文件系统的元数据,记录文件被切成多少块、存在哪些机器上 | 图书管理员,知道每本书被撕成几页,每页在哪本书里 |
| JobTracker (MapReduce的Master) | 接收用户提交的计算任务,拆分成小任务,分配给Slave执行,并监控进度 | 项目总指挥,把大工程拆成小任务,分给工人,盯着进度 |
Slave节点(小弟)—— 负责实际干活
| 角色 | 职责 | 比喻 |
|---|---|---|
| DataNode (HDFS的Slave) | 实际存储文件的数据块,并定期向NameNode汇报 | 书架管理员,手里拿着一些书页 |
| TaskTracker (MapReduce的Slave) | 接收JobTracker分配的任务,启动子进程执行Map或Reduce任务 | 工人,领到任务后开始干活 |
3. 数据本地化——分布式计算的精髓
你文档里有一句很重要的话:“TaskTracker根据应用要求来结合本地数据执行Map任务”
这句话背后是分布式计算的核心思想:计算向数据移动,而不是数据向计算移动。
想象一下:
- 传统做法:把1TB数据从100台机器传到1台机器上计算 → 网络拥堵,效率极低
- Hadoop做法:把计算程序传到100台机器上,每台机器只计算自己本地的那10GB数据 → 速度快,网络压力小
这就是数据本地化,也是分布式计算能处理海量数据的关键。
第四讲:一个完整的MapReduce计算流程
假设我们要统计一本100万页的书中,每个单词出现的次数(WordCount)。用Hadoop怎么做?
- 切分数据(HDFS层面)
- 书被自动切成1000块,每块1000页,分散存在100台Slave的DataNode上
- 提交任务
- 用户提交统计任务给JobTracker(Master)
- 任务拆分
- JobTracker把任务拆成1000个Map任务(每块数据一个Map任务)
- JobTracker尽量把Map任务分配到存有对应数据块的机器上(数据本地化)
- Map阶段(分头统计)
- 每台Slave的TaskTracker启动Map任务,读取本地那1000页
- 统计出”hello: 50次, world: 30次…”等局部结果
- 把结果暂存到本地磁盘
- Shuffle阶段(中间整理)
- 系统把相同单词的统计结果,分发到同一台机器准备汇总
- Reduce阶段(汇总结果)
- Slave启动Reduce任务,收集所有Map输出的中间结果
- 合并得到最终结果:”hello: 5000次, world: 3000次…”
- 返回结果
- 最终结果写回HDFS
第五讲:分布式计算的应用场景
| 领域 | 典型应用 | 说明 |
|---|---|---|
| 搜索引擎 | 网页抓取、建立索引 | Google最早就是用分布式计算做搜索 |
| 大数据分析 | 用户行为分析、推荐系统 | 电商、短视频的”猜你喜欢” |
| 科学计算 | 基因测序、天文数据处理 | 计算量巨大,单机无法完成 |
| 机器学习 | 模型训练 | 用大量数据训练AI模型 |
总结:一句话概括分布式计算集群
分布式计算集群 = 一个总指挥(Master)+ 一群工人(Slaves)+ 一个拆碎存储的分布式文件系统(HDFS)+ 一套拆碎计算的框架(MapReduce)。它的存在,是为了让成千上万台机器像一台超级计算机一样,解决单机永远算不完的问题。
补充:现代分布式计算生态
你文档里提到的是经典的Hadoop。现在生态已经非常丰富:
- Hadoop:离线批处理(适合处理TB/PB级数据,但速度较慢)
- Spark:内存计算(比Hadoop快10-100倍,适合迭代计算)
- Flink:实时流计算(数据一来就处理,适合实时监控)
- MPI:高性能科学计算(传统HPC领域)
但无论工具怎么变,核心思想没变:分而治之,并行计算,数据本地化。
发表回复