好的,我来把这段关于 Keepalived 的文档内容,逐段进行深度详细化。我会保留原文的严谨结构,同时加入更多的原理阐释、场景比喻和细节补充,让你不仅能读懂,还能讲明白。
Keepalived 深度详细解析
开篇:Keepalived 的定位——轻量级高可用解决方案
原文:
Keepalived是Linux下一个轻量级的高可用解决方案,它与HACMP、RoseHA实现的功能类似,都可以实现服务或者网络的高可用,但是又有差别:HACMP是一个专业的、功能完善的高可用软件,它提供了HA软件所需的基本功能,比如心跳检测和资源接管,监测集群中的系统服务,在群集节点间转移共享IP地址的所有者等,HACMP功能强大,但是部署和使用相对比较麻烦,同时也是商业化软件;与HACMP相比,Keepalived主要是通过虚拟路由冗余来实现高可用功能,虽然它没有HACMP功能强大,但Keepalived部署和使用非常简单,所有配置只需一个配置文件即可完成。这也是本课程重点介绍Keepalived的原因。
深度解析:
1. 什么是”轻量级”?
这里的”轻量级”主要体现在三个维度:
| 维度 | Keepalived | HACMP/RoseHA |
|---|---|---|
| 部署复杂度 | 一个配置文件搞定 | 需要安装多个包、配置多个文件 |
| 资源占用 | 内存占用小(几十MB) | 内存占用大(几百MB甚至更多) |
| 功能范围 | 专注于IP漂移和健康检查 | 完整的资源管理(磁盘、文件系统、IP、服务等) |
2. 为什么用Keepalived而不是HACMP?
- HACMP(IBM产品)/RoseHA: 像一辆重型卡车——能拉很多东西,功能强大,但需要专业司机,维护成本高
- Keepalived: 像一辆皮卡——虽然拉不了太多,但日常够用,操作简单,一个人就能开
3. 核心结论:
Keepalived走的是”小而美“的路线。如果你的需求主要是保证服务IP不中断,Keepalived是最佳选择。如果需要管理复杂的资源依赖(如先挂盘、再启IP、最后启数据库),那才需要考虑HACMP这样的重型方案。
第二讲:Keepalived的用途——双重身份
原文:
Keepalived起初是为LVS设计的,专门用来监控集群系统中各个服务节点的状态。它根据layer3, 4 & 5交换机制检测每个服务节点的状态,如果某个服务节点出现异常,或工作出现故障,Keepalived将检测到,并将出现故障的服务节点从集群系统中剔除,而在故障节点恢复正常后,Keepalived又可以自动将此服务节点重新加入到服务器集群中,这些工作全部自动完成,不需要人工干涉,需要人工完成的只是修复出现故障的服务节点。
Keepalived后来又加入了VRRP的功能,VRRP是Virtual Router Redundancy Protocol(虚拟路由器冗余协议)的缩写,它出现的目的是为了解决静态路由出现的单点故障问题,通过VRRP可以实现网络不间断地、稳定地运行。因此,Keepalived一方面具有服务器状态检测和故障隔离功能,另一方面也具有HA cluster功能。
深度解析:
1. Keepalived的双重身份
这是一个非常关键的理解点。Keepalived其实”身兼两职”:
| 身份 | 功能 | 适用场景 | 比喻 |
|---|---|---|---|
| 身份一:LVS管理工具 | 监控后端服务器状态,动态调整LVS转发列表 | 配合LVS搭建负载均衡集群 | 快递分拣线的”质检员” |
| 身份二:高可用软件 | 通过VRRP实现VIP漂移,保证入口不中断 | 保护Nginx/MySQL/任何单点服务 | 核心业务的”替身保镖” |
2. 健康检查的”三层机制”(layer3,4&5)
文档提到”根据layer3,4&5交换机制检测”,这是什么意思?
| 层级 | 检查方式 | 例子 | 发现的问题 |
|---|---|---|---|
| Layer3(网络层) | Ping测试(ICMP) | 检查IP是否可达 | 服务器宕机、网线断开 |
| Layer4(传输层) | 端口连通性测试 | 检查80端口是否开放 | 服务进程挂了,端口监听消失 |
| Layer5(应用层) | 应用协议检查 | HTTP GET请求,检查返回码是否为200 | 服务进程在,但业务逻辑卡死 |
实际场景:
- 如果服务器宕机了,Layer3检查就会发现
- 如果Nginx进程挂了,Layer4检查就会发现(80端口不通)
- 如果Nginx还在,但返回的页面是”500 Internal Error”,Layer5检查就会发现
3. 自动化的价值
文档强调”这些工作全部自动完成,不需要人工干涉”。这在生产环境中意味着:
- 凌晨3点:一台后端服务器内存溢出,Keepalived自动将其剔除
- 凌晨3点05分:运维人员还在睡觉,但业务毫无影响
- 早上9点:运维上班后,去修复那台故障服务器即可
这就是高可用集群的核心理念:把故障对业务的影响降到最低,给运维人员留出充足的修复时间。
第三讲:VRRP协议与工作原理——核心机制深度拆解
原文:
在现实的网络环境中,主机之间的通信都是通过配置静态路由(默认网关)完成的,而主机之间的路由器一旦出现故障,通信就会失败,因此,在这种通信模式中,路由器就成了一个单点瓶颈,为了解决这个问题,就引入了VRRP协议。
它是一种主备模式的协议,通过VRRP可以在网络发生故障时透明地进行设备切换而不影响主机间的数据通信,这其中涉及两个概念:物理路由器和虚拟路由器。
VRRP可以将两台或多台物理路由器设备虚拟成一个虚拟路由器,这个虚拟路由器通过虚拟IP(一个或多个)对外提供服务,而在虚拟路由器内部,是多个物理路由器协同工作,同一时间只有一台物理路由器对外提供服务,这台物理路由器被称为主路由器(处于MASTER角色)。一般情况下MASTER由选举算法产生,它拥有对外服务的虚拟IP,提供各种网络功能,如ARP请求、ICMP、数据转发等。而其他物理路由器不拥有对外的虚拟IP,也不提供对外网络功能,仅仅接收MASTER的VRRP状态通告信息,这些路由器被统称为备份路由器(处于BACKUP角色)。当主路由器失效时,处于BACKUP角色的备份路由器将重新进行选举,产生一个新的主路由器进入MASTER角色继续提供对外服务,整个切换过程对用户来说完全透明。
在一个虚拟路由器中,只有处于MASTER角色的路由器会一直发送VRRP数据包,处于BACKUP角色的路由器只接收MASTER发过来的报文信息,用来监控MASTER运行状态,因此,不会发生MASTER抢占的现象,除非它的优先级更高。而当MASTER不可用时,BACKUP也就无法收到MASTER发过来的报文信息,于是就认定MASTER出现故障,接着多台BACKUP就会进行选举,优先级最高的BACKUP将成为新的MASTER,这种选举并进行角色切换的过程非常快,因而也就保证了服务的持续可用性。
深度解析:
1. 为什么要VRRP?——从”一个网关”到”一群网关”
问题场景:
- 公司内部有100台电脑,都配置网关为
192.168.1.1(路由器A) - 如果路由器A坏了,所有电脑都无法上网
- 虽然有路由器B(IP
192.168.1.2)是好的,但电脑不认识它
VRRP的解决方案:
- 创建一个”虚拟路由器”,IP为
192.168.1.100(虚拟IP) - 告诉所有电脑:网关是
192.168.1.100 - 路由器A和B组成一个团队:谁活着,谁就代表
192.168.1.100干活 - 用户完全不知道后面有两台路由器
2. 两个核心概念的深度理解
| 概念 | 定义 | 比喻 | 关键点 |
|---|---|---|---|
| 物理路由器 | 真实的硬件设备,有自己的真实IP | 具体的某个保安 | 可能坏掉 |
| 虚拟路由器 | 逻辑概念,由VRRP创建,有虚拟IP | “保安队长”这个职位 | 永远存在 |
3. 选举机制详解
文档提到”MASTER由选举算法产生”,具体怎么选?
选举规则(按顺序):
- 优先级优先: 谁配置的优先级高,谁当MASTER(范围1-255,默认100)
- IP地址大者优先: 如果优先级相同,谁的真实IP大,谁当MASTER
4. VRRP报文通信机制
这是一个容易被忽视但很重要的细节:
| 角色 | 行为 | 比喻 |
|---|---|---|
| MASTER | 周期性发送VRRP通告报文(默认每秒1次) | 队长每隔1秒喊一嗓子”我还活着!” |
| BACKUP | 只接收,不发送;如果连续3秒没听到喊声,认为队长死了 | 队员竖起耳朵听,听不到就准备接班 |
5. 抢占机制详解
文档中有一句关键的话:“不会发生MASTER抢占的现象,除非它的优先级更高”
这句话包含了两层意思:
| 情况 | 是否抢占 | 原因 |
|---|---|---|
| 新节点加入,但优先级低于当前MASTER | 不抢占 | 尊重现任,安心当BACKUP |
| 新节点加入,优先级高于当前MASTER | 抢占 | 能力强者上,保证最优配置 |
6. 切换速度分析
文档说”切换过程非常快”,到底有多快?
切换时间计算公式:
切换时间 = (3 × 通告间隔) + 抖动量- 默认通告间隔 = 1秒
- 默认切换时间 ≈ 3秒
优化建议:
- 如果追求更快切换,可以设置
advert_int 0.2(200毫秒) - 切换时间 ≈ 0.6秒
- 注意: 太快的切换可能导致网络抖动时误判
第四讲:Keepalived的体系结构——模块化设计深度解析
原文:
Keepalived是一个高度模块化的软件,结构简单,但扩展性很强,下图是官方给出的Keepalived体系结构拓扑图。
可以看出,Keepalived的体系结构从整体上分为两层,分别是用户空间层(User Space)和内核空间层(Kernel Space)。下面介绍Keepalived两层结构的详细组成及实现的功能。
内核空间层处于最底层,它包括IPVS和NETLINK两个模块。IPVS模块是Keepalived引入的一个第三方模块,通过IPVS可以实现基于IP的负载均衡集群。IPVS默认包含在LVS集群软件中。
Keepalived最初就是为LVS提供服务的,由于Keepalived可以实现对集群节点的状态检测,而IPVS可以实现负载均衡功能,因此,Keepalived借助于第三方模块IPVS就可以很方便地搭建一套负载均衡系统。
在这里有个误区,由于Keepalived可以和IPVS一起很好地工作,因此很多初学者都以为Keepalived就是一个负载均衡软件,这种理解是错误的。
在Keepalived中,IPVS模块是可配置的,如果需要负载均衡功能,可以在编译Keepalived时打开负载均衡功能,反之,也可以通过配置编译参数关闭。
NETLINK模块主要用于实现一些高级路由框架和一些相关的网络功能,完成用户空间层Netlink Reflector模块发来的各种网络请求。
用户空间层位于内核空间层之上,Keepalived的所有具体功能都在这里实现。
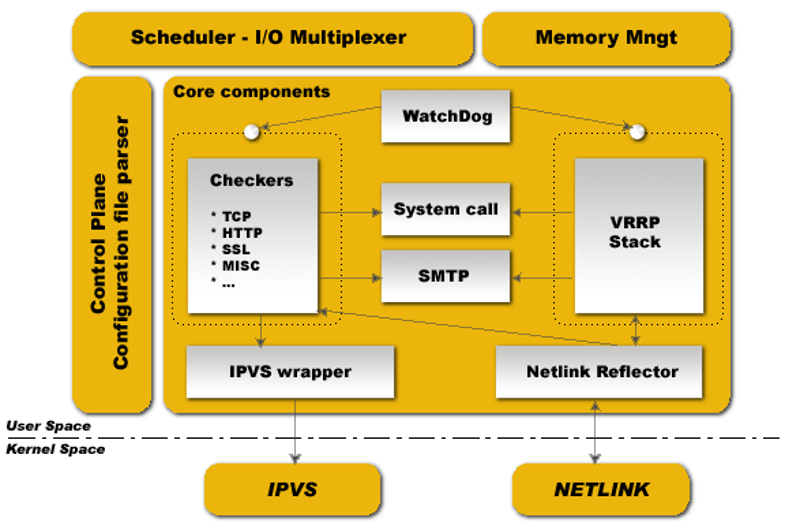
深度解析:
1. 为什么分成”用户空间”和”内核空间”?
这是Linux系统设计的通用理念:
| 层次 | 权限 | 特点 | 比喻 |
|---|---|---|---|
| 用户空间 | 受限 | 容易开发、调试,安全 | 公司管理层(做决策) |
| 内核空间 | 完全 | 直接操作硬件,性能高 | 一线执行层(动手干活) |
2. 内核空间层的两个模块详解
| 模块 | 全称 | 功能 | 比喻 |
|---|---|---|---|
| IPVS | IP Virtual Server | 真正的流量转发引擎,工作在操作系统内核,性能极高 | 快递自动分拣机 |
| NETLINK | Netlink Socket | 内核与用户空间的通信通道,用于配置网络接口、路由表等 | 管理层到一线的”传令兵” |
3. 用户空间层的组件详解
根据你提供的架构图,用户空间层包含以下核心组件:
| 组件 | 功能 | 比喻 |
|---|---|---|
| Configuration File Parser | 读取并解析keepalived.conf配置文件 | 翻译官,把人的指令转成机器能懂的语言 |
| Checkers | 执行健康检查(TCP/HTTP/SSL/MISC等) | 哨兵,时刻盯着后端服务器 |
| VRRP Stack | VRRP协议的核心实现,决定主备角色 | 选举委员会 |
| IPVS Wrapper | 封装对IPVS模块的操作指令 | IPVS的远程控制器 |
| Netlink Reflector | 封装对NETLINK模块的操作指令 | NETLINK的远程控制器 |
| WatchDog | 监控各个进程的健康状态,发现异常则重启 | 监工,盯着所有人别偷懒 |
| SMTP | 发送邮件通知 | 报警器 |
| System Call | 系统调用接口 | 申请特权操作的窗口 |
4. 最关键的一句话:澄清误区
文档特别强调:“很多初学者都以为Keepalived就是一个负载均衡软件,这种理解是错误的”
为什么会有这个误区?
因为Keepalived确实可以配合LVS搭建负载均衡系统,而且配合得非常好。但我们需要分清楚:
| 场景 | 负责负载均衡的是 | Keepalived的角色 |
|---|---|---|
| Keepalived + LVS | LVS(真正的负载均衡器) | 健康检查 + 高可用 |
| Keepalived + Nginx | Nginx(真正的负载均衡器) | 高可用(保护Nginx) |
| Keepalived alone | 没有负载均衡 | 纯高可用(保护VIP) |
5. IPVS模块的”可选性”
文档提到”IPVS模块是可配置的”,这意味着:
# 编译时启用IPVS(支持负载均衡)
./configure --enable-lvs
# 编译时禁用IPVS(纯高可用)
./configure --disable-lvs为什么可以禁用?
- 如果你只需要用Keepalived保护Nginx/MySQL,根本用不到IPVS
- 禁用后可以减小软件体积,减少不必要的内核交互
总结:Keepalived的核心价值
- 双重身份: 既是LVS的”金牌搭档”,又是独立的高可用软件
- 核心机制: VRRP协议实现IP漂移,健康检查保障后端服务可用性
- 模块化设计: 各组件各司其职,结构清晰,易于扩展
- 配置简单: 一个配置文件搞定所有,这是它流行的重要原因
- 轻量高效: 资源占用少,适合各种规模的环境
一句话总结:
Keepalived = VRRP协议实现(高可用)+ 健康检查机制(监控)+ 可选IPVS集成(负载均衡管理)
发表回复